NB: this post was last updated 17 March 2025. In general, I add new sites but don't remove old sites that are no longer live. This post is now supplemented with another on National approaches to crowdsourcing / citizen science. I've also shared a 2015 list of 'participatory digital heritage sites' that includes many crowdsourcing sites. Contact me via my main website contact page to suggest a site.
It's all too easy to overlook international crowdsourcing projects in languages other than English so I thought I'd collect some projects related to cultural heritage, history and science here (following my definition of crowdsourcing in cultural heritage as 'asking the public to help with tasks that contribute to a shared, significant goal or research interest related to cultural heritage collections or knowledge'). This list is drawn from my PhD research, but this is a fast-moving field and I was focusing on early modern England, so inevitably this list will be missing loads of examples. Please suggest links to help people discover new projects! Also, I'm often taking my best guess at the correct translation for terms, so please correct me if I've misunderstood.
If you're interested in crowdsourcing in cultural heritage, my edited volume has chapters with lessons learnt from a range of projects.
- The Zooniverse platform has a post on projects that have been translated into languages including Arabic, Bangla, Chinese, Czech, Dutch, French, German, Greek, Hindi, Hungarian, Indonesian, Italian, Japanese, Korean, Polish, Portuguese, Russian, Spanish and Ukrainian.
- AfroCrowd is 'an outreach initiative and Wikimedia usergroup which seeks to increase awareness of the Wikimedia and free knowledge, culture, and software movements among potential editors of African descent' with links to Haitian, Igbo, Twi, Yoruba, Garifuna, French, Spanish Wikipedia and more
- Moravian Lives offers text transcription in English, German and Swedish. Thanks @KatherineFaull for sharing!
- DigiTalkoot has been and gone (launched February 2011, closed November 2012) but was a great example of tasks that helped correct scanned text for the Historical Newspaper Library of The National Library of Finland.
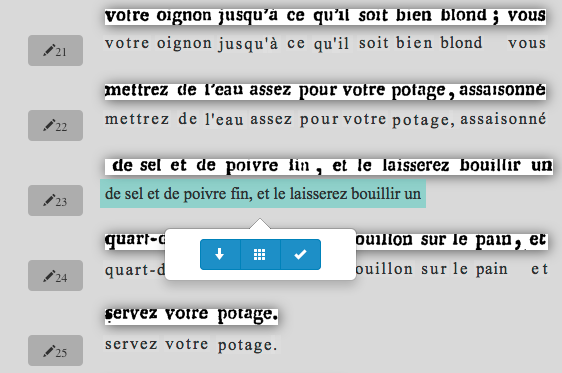
- The National Library of France was involved in a pilot project called 'Correct' to correct errors in scanned documents. Further information: Josse, Isabelle. La bnF engagée dans un projet de R&D pour la conception de la plateforme Correct (Correction et enrichissement collaboratifs de textes). Bulletin des bibliothèques de France. [en ligne], n° 5, 2013, http://bbf.enssib.fr/consulter/bbf-2013-05-0037-008. ISSN 1292-8399
- The French version of WikiSource has lots of books to be transcribed.
- There's a German-language transcription project for the Digitale Edition Nachlasses Franz Brümmer and related Refine!Editor – it looks like it was designed for student participation and that interested people can register to transcribe via the contact page. Via Simone Waidmann, “Erschließung Historischer Bestände Mittels Crowdsourcing: Eine Analyse Ausgewählter Aktueller Projekte,” Perspektive Bibliothek 3, no. 1 (2014): 33–58, http://journals.ub.uni-heidelberg.de/index.php/bibliothek/article/view/14020.
- ARTigo is a German project, with English, French and German-language interfaces. Tag images of artworks through six different games! They also have an active German-language blog.
- Red een Portret ('Save a portrait') from the Amsterdam City Archives – help identify photographs or donate money to support the project
- Ajapaik is an Estonian project asking for help identifying historical images.
- Transcriptorium has several non-English datasets you can review to help train their handwriting recognition software
- Ancient Lives is the site for you if you want to learn the ancient Greek alphabet while transcribing papyri.
- Arthur Schnitzler digital 'is using the Transcribo software to produce a digital transcription and annotation of both typescript and manuscript material'.
- The Bracero History Archive is collecting oral histories in both English and Spanish.
- Cymru1900Wales and Cynefin are both working on Welsh maps and have Welsh and English-language interfaces
- Danish Demographic Database includes transcriptions from volunteers.
- Europeana 1914-1918 and Europeana 1989 are collecting records in many European languages. Wir Waren So Frei is also collecting records about the fall of the Berlin Wall.
- You can index records in many languages on Ancestry's World Archives Project.
- You can also help Improve Google Translate (not really a heritage project but it helps other projects). Similarly, you can help translate the crowdsourcing platform Pybossa into Italian or learn a language while translating text with Duolingo.
- You can 'use the site's comment features to share any supplements (such as citations to published works, transcription of notes not yet addressed, authorial attribution for a particular text, etc.) or remarks on the significance of the manuscript codices and contents' to help Islamic Manuscripts at Michigan.
- Itinera Nova has volunteer transcribers
- You can help correct and annotate records from 'more than 100 European archives' in the Monasterium.Net collaborative archive.
- Help transcribe Dutch natural history collections with Naturalis.
- Transcribe Swedish census records from 1760 with Stockholms Stad.
- Help index Dutch records with Vele Handen.
- The Norwegian The Digital Inn is for 'sources/documents digitised by institutions, associations or persons outside the organisation of the National Archives of Norway' – a fantastic way of collecting the work that community historians are doing
- The Danish Politiets registerblade – help transcribe records from the city register.
- The Croatian Museum of Broken Relationships
- Dry stone walls crowdsourced
- The British Library's LibCrowds Convert-a-Card card catalogue transcription project has Pinyin and Indonesian cards for transcription
- The National Library of Israel has a crowdsourcing project in Hebrew (via this Pybossa post)
- Sefaria, 'a living library of Jewish texts', 'building a free living library of Jewish texts and their interconnections, in Hebrew and in translation'
- Footprints, Jewish books through time and place
- La Grande Collecte is collecting French records about the First World War
- KB Kranten – Editor, help correct digitized newspapers OCR. A collaboration between Dutch national library & Meertens Institute
- Edvard Munchs tekster
- Demogen, from the State Archives of Belgium
- The Estonian Digitalgud – digital 'working bees' to collect information about historical images
- Index records about Estonian soldiers in the two World Wars via Eestlased Esimeses maailmasõjas
- An L-Crowd Project: TranscribeJP@Japanese Association for DigitalHumanities and Microtasks
- Estoria de Espanna and Estoria de Espanna Project blog, 'aiming to transcribe these 13th-century manuscripts, tagging them (especially for person names and toponyms) so as to reconstruct afterwards biographies and itineraries'.
- Les herbonautes, a French herbarium transcription project led by the Paris Natural History Museum
- Loki is a Finnish project on maritime, coastal history
- Swedish Species Information Centre 'Species Observations' (hat tip Sanja Halling)
- sandbyborg.se, http://www.platsr.se, http://www.crowdculture.se (hat tip Max Valentin)
- Donald Sturgeon @donaldsturgeon said: '@chinesetextproj has an active Wiki section in which Chinese texts are transcribed/OCR post-corrected & annotated: http://ctext.org/wiki.pl?if=en'. Find out more about transcribing, proof-reading, translations, discussion and other forms of contribution on their 'Ways to Help' page.
- Danish Family Search projects include indexing church, school and census records, recording street names and categorising professions.
- Danish National Archives crowdsourcing https://cs.sa.dk/?locale=en and overview page (suggested by Alex Mendes)
- Crowd-correction platform Kokos was 'built to improve the OCR quality of the digitized yearbooks of the Swiss Alpine Club (SAC) from the 19th century', working with French and German
- j. Hocker @julianhocker said, 'take a look at interlinking.bbf.dipf.de, it is a project about a encyclopedia for children that was printed in the 19th century'
- @BenWBrum pointed me to a Chinese character transcription project on the Smithsonian's platform then @TranscribeSI pointed out some additional Chinese and Japanese-language projects
- VinKo ('Varieties in Contact') is an online questionnaire developed at the Universities of Trento and Verona to gather information about the minority languages and dialects spoken in the area between Innsbruck and Verona
- @BenWBrum's From the Page platform has French and Spanish language pages from the Louisiana Historical Center at the New Orleans Jazz Museum for transcription
- @Lisa_Chupin shared Noms de Vendée, aiming to deepen engagement as well as enrich and correct archival records.
- Judaica DH at Penn @judaicadh shared, 'Scribes of the Cairo Geniza classifies/transcribes Hebrew & Arabic fragments' https://www.scribesofthecairogeniza.org/
- http://openbolshoi.ru/ (Russian)
- Sweden's Digitala forskarsalen ('digital research hall') includes indexing and transcription projects
- The Dutch hetvolk.org set of tools / projects (thanks Enno Meijers)
- 'Maak de Surinaamse slavenregisters openbaar', crowdfunding/crowdsourced transcription project c 2017 (original instructions page) using hetvolk
- China – the Shengxuanhuai Manuscript Transcription Initiative, aka the Transcribe Sheng project
- The French RECITAL (Contribuez librement à une expérience de transcription participative des REgistres de la Comédie-ITALienne de Paris au XVIIIe siècle). 'Ces documents uniques donnent à réviser l'état des connaissances sur l'économie du spectacle et toute l'histoire culturelle du XVIIIe. Votre aide nous est précieuse' https://recital.univ-nantes.fr/
- Kino in der DDR at the University of Erfurt collects information, experience and documents on the cinema history of East Germany. Interview with the project leaders (in German).
- Also possibly other academic German citizen humanities projects
- Nikola Dyordyevich shared the Serbian 'Улице Панчева' / 'Streets of Panchevo' project with old maps, images, etc. Serbian site: https://улицепанчева.срб. English site: https://ulicepanceva.in.rs/en/
- “All Tolstoy in one click” was a Russian language crowdsourcing project that asked volunteers to correct OCR layouts and transcription. Technical details; main site https://readingtolstoy.ru.
- The Czech/German (Bavarian) PhotoStruk, crowdsourcing information related to archival photographs of now-destroyed sites on the Czech – Bavarian border. More inL ‘Geoinformatics and Crowdsourcing in Cultural Heritage: A Tool for Managing Historical Archives’. Agris On-Line Papers in Economics and Informatics https://doi.org/10.7160/aol.2018.100207.
- Crowdsourcing Wien, a platform from the Austrian Wien Museum und Wienbibliothek im Rathaus. Collections include playbills and letters.
English-language projects tend to be easier to find, but for completeness:
UK – irecord.org.uk/ (thanks Rita Singer @_bydbach_)
USA – archives.gov/citizen-archivist and weather.gov/cle/CWOP (thanks @BuffaloResearch), crowd.loc.gov, transcription.si.edu/
- 'Your project goes here' – what have I missed?