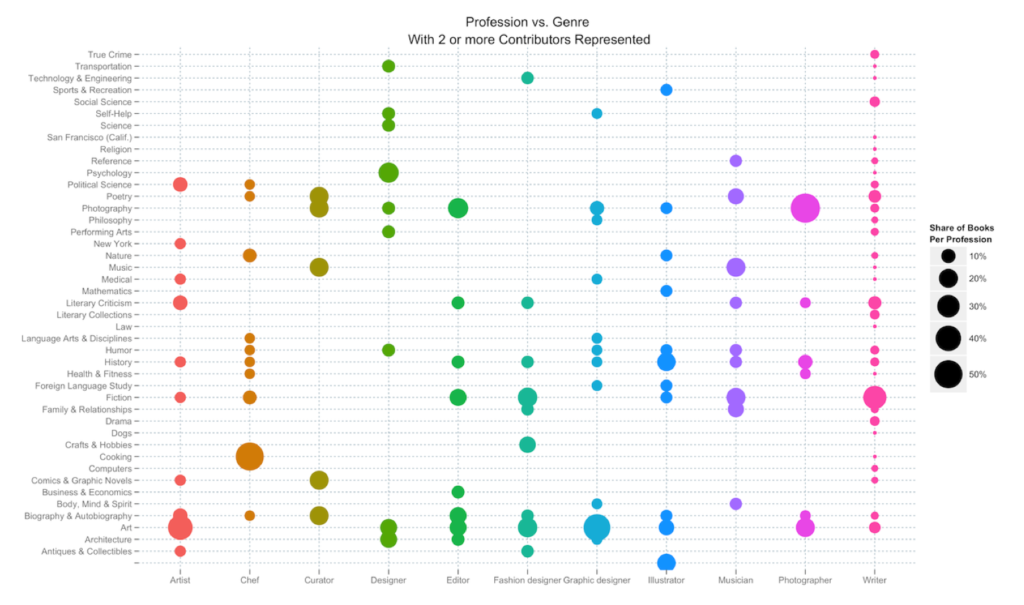
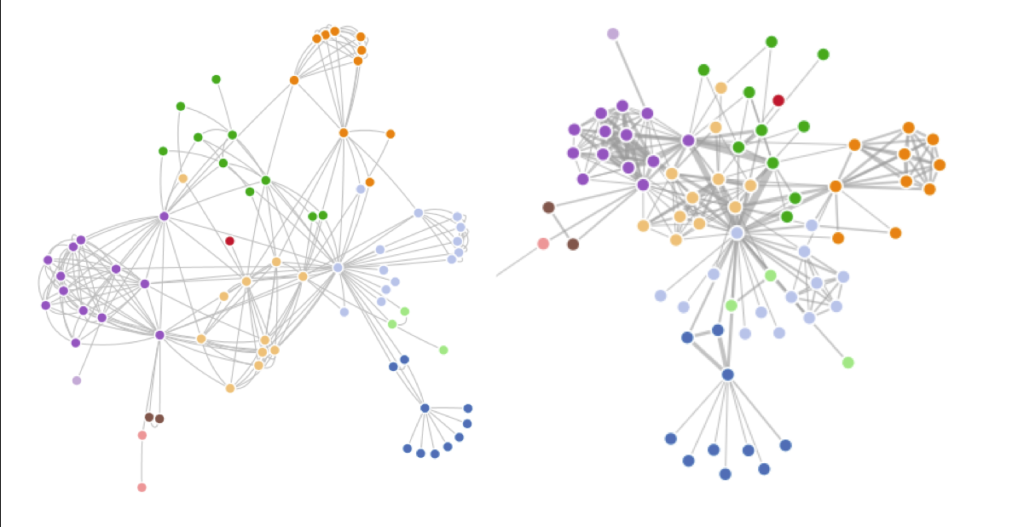
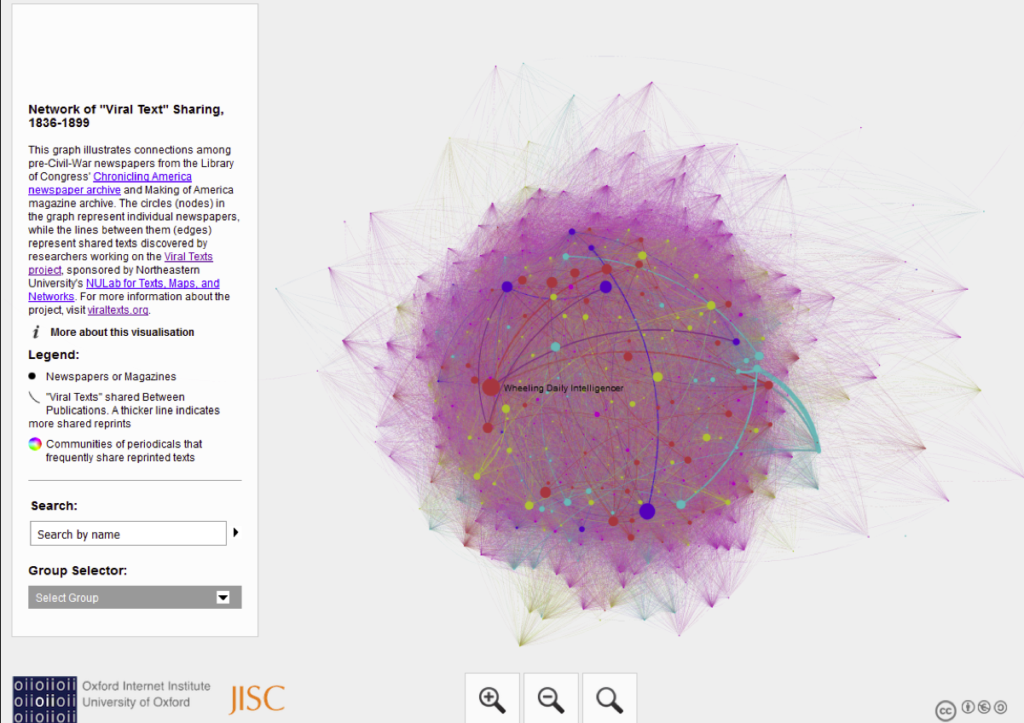
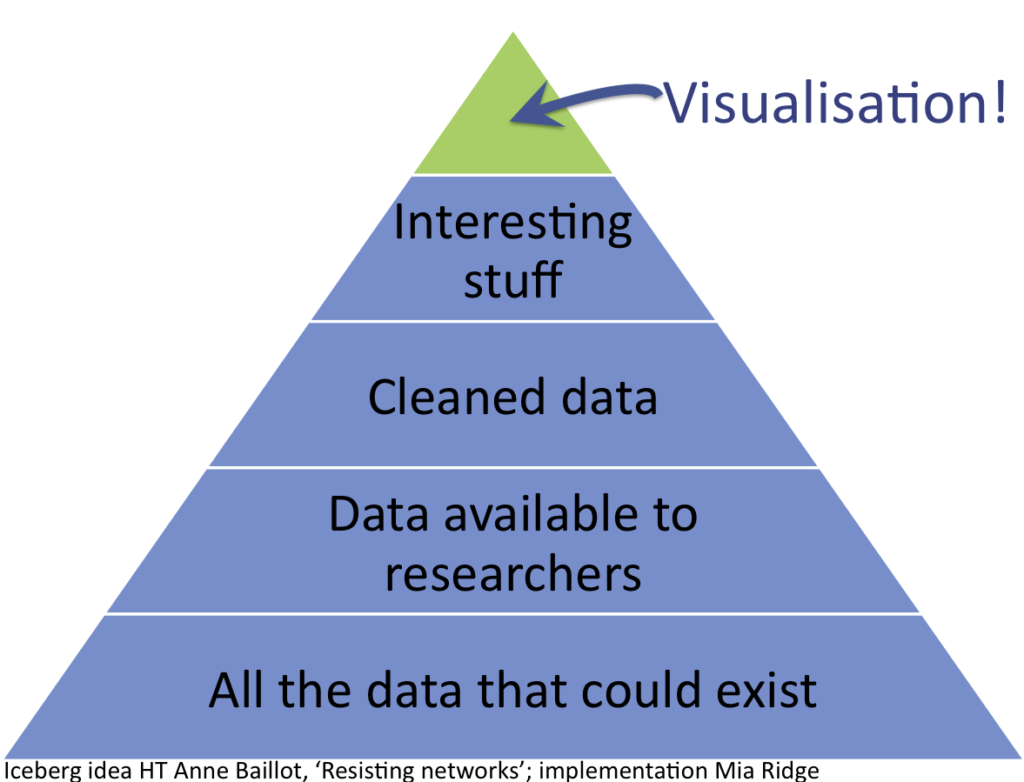
It's not easy to find the abstracts for presentations within panels on the Digital Humanities 2019 (DH2019) site, so I've shared mine here. The panel was designed to bring together range of interdisciplinary newspaper-based digital humanities and/or data science projects, with 'provocations' from two senior scholars who will provide context for current ambitions, and to start conversations among practitioners.
Short Paper: Living with Machines
Paper authors: Mia Ridge, Giovanni Colavizza with Ruth Ahnert, Claire Austin, David Beavan, Kaspar Beelens, Mariona Coll Ardanuy, Adam Farquhar, Emma Griffin, James Hetherington, Jon Lawrence, Katie McDonough, Barbara McGillivray, André Piza, Daniel van Strien, Giorgia Tolfo, Alan Wilson, Daniel Wilson.
Living with Machines is a five-year interdisciplinary research project, whose ambition is to blend data science with historical enquiry to study the human impact of the industrial revolution. Set to be one of the biggest and most ambitious digital humanities research initiatives ever to launch in the UK, Living with Machines is developing a large-scale infrastructure to perform data analyses on a variety of historical sources, and in so doing provide vital insights into the debates and discussions taking place in response to today’s digital industrial revolution.
Seeking to make the most of a self-described 'radical collaboration', the project will iteratively develop research questions as computational linguists, historians, library curators and data scientists work on a shared corpus of digitised newspapers, books and biographical data (census, birth, death, marriage, etc. records). For example, in the process of answering historical research questions, the project could take advantage of access to expertise in computational linguistics to overcome issues with choosing unambiguous and temporally stable keywords for analysis, previously reported by others (Lansdall-Welfare et al., 2017). A key methodological objective of the project is to 'translate' history research questions into data models, in order to inspect and integrate them into historical narratives. In order to enable this process, a digital infrastructure is being collaboratively designed and developed, whose purpose is to marshal and interlink a variety of historical datasets, including newspapers, and allow for historians and data scientists to engage with them.
In this paper we will present our vision for Living with Machines, focusing on how we plan to approach it, and the ways in which digital infrastructure enables this multidisciplinary exchange. We will also showcase preliminary results from the different research 'laboratories', and detail the historical sources we plan to use within the project.
The Past, Present and Future of Digital Scholarship with Newspaper Collections
Mia Ridge (British Library), Giovanni Colavizza (Alan Turing Institute)
Historical newspapers are of interest to many humanities scholars, valued as sources of information and language closely tied to a particular time, social context and place. Following library and commercial microfilming and, more recently, digitisation projects, newspapers have been an accessible and valued source for researchers. The ability to use keyword searches through more data than ever before via digitised newspapers has transformed the work of researchers.[1]
Digitised historic newspapers are also of interest to many researchers who seek large bodies of relatively easily computationally-transcribed text on which they can try new methods and tools. Intensive digitisation over the past two decades has seen smaller-scale or repository-focused projects flourish in the Anglophone and European world (Holley, 2009; King, 2005; Neudecker et al., 2014). However, just as earlier scholarship was potentially over-reliant on The Times of London and other metropolitan dailies, this has been replicated and reinforced by digitisation projects (for a Canadian example, see Milligan 2013).
In the last years, several large consortia projects proposing to apply data science and computational methods to historical newspapers at scale have emerged, including NewsEye, impresso, Oceanic Exchanges and Living with Machines. This panel has been convened by some consortia members to cast a critical view on past and ongoing digital scholarship with newspapers collections, and to inform its future.
Digitisation can involve both complexities and simplifications. Knowledge about the imperfections of digitisation, cataloguing, corpus construction, text transcription and mining is rarely shared outside cultural institutions or projects. How can these imperfections and absences be made visible to users of digital repositories? Furthermore, how does the over-representation of some aspects of society through the successive winnowing and remediation of potential sources – from creation to collection, microfilming, preservation, licensing and digitisation – affect scholarship based on digitised newspapers. How can computational methods address some of these issues?
The panel proposes the following format: short papers will be delivered by existing projects working on large collections of historical newspapers, presenting their vision and results to date. Each project is at different stages of development and will discuss their choice to work with newspapers, and reflect on what have they learnt to date on practical, methodological and user-focused aspects of this digital humanities work. The panel is additionally an opportunity to consider important questions of interoperability and legacy beyond the life of the project. Two further papers will follow, given by scholars with significant experience using these collections for research, in order to provide the panel with critical reflections. The floor will then open for debate and discussion.
This panel is a unique opportunity to bring senior scholars with a long perspective on the uses of newspapers in scholarship together with projects at formative stages. More broadly, convening this panel is an opportunity for the DH2019 community to ask their own questions of newspaper-based projects, and for researchers to map methodological similarities between projects. Our hope is that this panel will foster a community of practice around the topic and encourage discussions of the methodological and pedagogical implications of digital scholarship with newspapers.
[1] For an overview of the impact of keyword search on historical research see (Putnam, 2016) (Bingham, 2010).