I've shared these at work and thought it might be helpful to post my notes from the launch of the Museum Data Service at Bloomberg last week in public too.
The MDS aggregates museum (and museum-like) metadata, encouraging use by data scientists, researchers, the public, etc. The MDS doesn't include images, but link to them if they're available on museum websites. (When they open APIs, presumably people could build their own image-focused site on the service).
It was launched by Sir Chris Bryant (Minister of State at the Department for Science, Innovation and Technology and the Department for Culture, Media and Sport) who said it could be renamed the ‘Autolycus project', after Shakespeare's snapper up of unconsidered trifles. He presented it as a rare project that sits between his two portfolios.
Allan Sudlow of the AHRC (one of the funders) described it as secure, reliable digital infrastructure for GLAMs, especially providing security and sustainability for smaller museums, and meeting a range of needs, including reciprocal relationships between museums and researchers. He positioned it as part of the greater ecosystem, infrastructure for digital creativity and innovation. Kevin Gosling (Collections Trust) mentioned that it helps deliver the Mendoza Report's ‘dynamic collections'.
I'd seen a preview over the summer and was already impressed with the way it builds on decades of experience managing and aggregating real museum data between internal and centralised systems. They've thought hard about what museums really need to represent their collections, what they find hard about managing data/tech, and what the MDS can do to lighten that load.
The MDS can operate as a backup of last resort, including data that isn't shared even inside the organisation. They're not trying to pre-shape the data in any way, to allow for as many uses as possible (apart from the process of mapping specific museum data to their fields). It has persistent links (fundamental to FAIR data and citing records). They're linking to wikidata (and creating records there where necessary). APIs will be available soon (which might finally mean an end to the ‘does every museum need an API' debate).
The site https://museumdata.uk/ has records for institutions, collections, object records, and ‘new and enhanced data' about object records (e.g. exhibition interpretation, AI-generated keywords). It feels a bit like a rope bridge – lightweight but strong and flexible infrastructure that meets a community need.
I admire the way they've used just enough technology to deliver it both practically and elegantly. They've also worked hard on explaining why it matters to different stakeholders, and finding models for funding and sustainability.
On a personal note, the launch was a bit like a school reunion (if you went to a particularly nerdy school). It was great to see people like David Dawson, Richard Light and Gordon McKenna there (plus Andy Ellis, Ross Parry and Kevin Gosling) as they'd shared visions for a service like this many years ago, and finally got to see it go live.
I'm giving a lecture on 'crowdsourcing at the British Library' for students on UCL's MSc Sustainable Heritage taking the course 'Crowd-Sourced and Citizen Data for Cultural Heritage' (BENV0114).
As some links at the British Library are still down, I've put the web archive versions into a post, along with other links included in my talk:
I’ve been meaning to write this post since May 2022, when I was invited to present at a SCONUL event on ‘AI for libraries’. It’s hard to write anything about AI that doesn’t feel outdated before you hit ‘post’, especially since ChatGPT made generative AI suddenly accessible interesting to ‘ordinary’ people. Some of the content is now practically historical but I'm posting it partly because I liked their prompts, and it's always worth thinking about how quickly some things change while others are more constant.
Prompt 1. Which library AI projects (apart from your own) have most sparked your interest over recent years? Library of Congress 'Humans in the Loop: Accelerating access and discovery for digital collections initiative' experiments and recommendations for 'ethical, useful, and engaging' work https://labs.loc.gov/work/experiments/humans-loop/
Understanding visitor comments at scale – sentiment analysis of TripAdvisor reviews https://medium.com/@CuriousThirst/on-artificial-intelligence-museums-and-feelings-598b7ba8beb6
Various 'machines looking through documents' research projects, including those from Living with Machines – reading maps, labelling images, disambiguating place names, looking for change over time
Prompt 2. Which three things would you advise library colleagues to consider before embarking on an AI project?
Think about your people. How would AI fit into existing processes? Which jobs might it affect, and how? What information would help your audiences? Can AI actually reliably deliver it with the data you have available?
AI isn't magic. Understand the fundamentals. Learn enough to understand training and testing, accuracy and sources of bias in machine learning. Try tools like https://teachablemachine.withgoogle.com
Consider integration with existing systems. Where would machine-created metadata enhancements go? Is there a granularity gap between catalogue records and digitised content?
Prompt 3. What do you see as the role for information professionals in the world of AI? Advocate for audiences • Make the previously impossible, possible – and useful!
Advocate for ethics • Understand the implications of vendor claims – your money is a vote for their values • If it's creepy or wrong in person, it's creepy or wrong in an algorithm (?)
'To see a World in a Grain of Sand' • A single digitised item can be infinitely linked to places, people, concepts – how does this change 'discovery'?
A TL;DR is that it's incredible how many of the projects discussed wouldn't have been possible (or less feasible) a year ago. Whisper and ChatGPT (4, even more than 3.5) and many other new tools really have brought AI (machine learning) within reach. Also, the fact that I can *copy and paste text from a photo* is still astonishing. Some fantastic parts of the future are already here.
Other thinking aloud / reflections on themes from the event: the gap between experimentation and operationalisation for AI in GLAMs is still huge. Some folk are desperate to move onto operationalisation, others are enjoying the exploration phase – thinking about it, knowing where you and your organisation each stand on that could save a lot of frustration! Bridging it is possible, but it takes dedicated resources (including quality checking) from multi-disciplinary teams, and probably the goal has to be big and important enough to motivate all the work required. In examples discussed at FF2023, the scale of the backlog of collection items to be processed is that big important thing that motivates work with AI.
It didn't come up as directly, perhaps because many projects are still pilots rather than in production, but I'm very interested in the practical issues around including 'enriched' data from AI (or crowdsourcing) in GLAM collections management / cataloguing systems. We need records that can be enriched with transcriptions, keywords and other data iteratively over time, and that can record and display the provenance of that data – but can your collections systems do that?
Making LLMs stick to content in the item is hard, 'hallucinations' and loose interpretations of instructions are an issue. It's so useful hearing about things that didn't work or were hard to get right – common errors in different types of tools, etc. But who'd have thought that working with collections metadata would involve telling bedtime stories to convince LLMs to roleplay as an expert cataloguer?
Workflows are vital! So many projects have been assemblages of different machine learning / AI tools with some manual checking or correction.
A general theme in talks and chats was the temptation to lower 'quality' to be able to start to use ML/AI systems in production. People are keen to generate metadata with the imperfect tools we have now, but that runs into issues of trust for institutions expected to publish only gold standard, expert-created records. We need new conventions for displaying 'data in progress' alongside expert human records, and flexible workflows that allow for 'humans in the loop' to correct errors and biases.
If we are in an 'always already transitional' world where the work of migrating from one cataloguing standard or collections management tool to another is barely complete before it's time to move to the next format/platform, then investing in machine learning/AI tools that can reliably manage the process is worth it.
'Data ages like wine, software like fish' – but it used to take a few years for software to age, whereas now tools are outdated within a few months – how does this change how we think about 'infrastructure'? Looking ahead, people might want to re-run processes as tools improve (or break) over time, so they should be modular. Keep (and version) the data, don't expect the tool to be around forever.
I ran a workshop and went to two others the day before the conference proper began. I've put photos from the workshop I ran with Thomas Padilla (originally proposed with Nora McGregor and Silvia Gutiérrez De la Torre too) on Co-Creating an AI Responsive Information Literacy Curriculum workshop on Flickr. You can check out our workshop prompts and links to the 'AI literacy' curricula devised by participants.
Fantastic Futures Day 1
Thomas Mboa opens with a thought-provoking keynote. Is AI in GLAMs a Pharmakon (a purification ritual in ancient Greece where criminals were expelled)? Phamakon can mean both medicine and poison.
Can we ensure cultural integrity alone, from our ivory tower?
How can we involve data-providers communities without exploiting them?
Al feeds on data, which in turn conveys biases. How can we ensure the quality of data?
Cultural integrity is a measure of the wholeness or intactness of material, whether it respects and honours traditional ownership, traditions and knowledge
Thomas Mboa finishes with 'Some Key actions to ensure responsible use of Al in GLAM':
Develop Ethical Guidelines and Policies
Address Bias and Ensure Inclusivity
Enhance Privacy and Data Security
Balance Al with Human Expertise
Foster Digital Literacy and Skills Development
Promote Sustainable and Eco-friendly Practices
Encourage Collaboration and Community Engagement
Monitor and Evaluate Al Impact:
Intellectual Property and Copyright Considerations:
Preserve Authenticity and Integrity]
I shared lessons for libraries and AI from Living with Machines then there was a shared presentation on Responsible AI and governance – transparency/notice and clear explanations; risk management; ethics/discrimination, data protection and security.
Mike Trizna (and Rebecca Dikow) on the Smithsonian's AI values statement. Why We Need an Al Values Statement – everyone at the Smithsonian involved in data collection, creation, dissemination, and/or analysis is a stakeholder – Our goal is to aspirationally and proactively strive toward shared best practices across a distributed institution. All staff should feel like their expertise matters in decisions about technology.
From Bart Murphy (and Mary Sauer Games)'s talk it seems OCLC are really doing a good job operationalising AI to deduplicate catalogue entries at scale, maintaining quality and managing cost of cloud compute; also keeping ethics in mind.
Next, Abigail Potter and Laurie Allen, Introducing the LC Labs Artificial Intelligence Planning Framework. I love that LC Labs do the hard work of documenting and sharing the material they've produced to make experimentation, innovation and implementation of AI and new technologies possible in a very large library that's also a federal body.
Abby talked about their experiments with generating catalogue data from ebooks, co-led with their cataloguing department.
A panel discussed questions like: how do you think about "right sizing" your Al activities given your organizational capacity and constraints? How do you think about balancing R&D / experimentation with applying Al to production services / operations? How can we best work with the commercial sector? With researchers? What do you think the role of LAMs should be within the Al sector and society? How can we leverage each other as cultural heritage institutions?
I liked Stu Snydman's description of organising at Harvard to address AI with their values: embrace diverse perspectives, champion access, aim for the extraordinary, seek collaboration, lead with curiosity. And Ingrid Mason's description of NFSA's question about their 'social licence' (to experiment with AI) as an 'anchoring moment'. And there are so many reading groups!
Some of the final talks brought home how much more viable ChatGPT 4 has made some tasks, and included the first of two projects trying to work around the fact that people don't provide good metadata when depositing things in research archives.
Fantastic Futures Day 2
Day 2 begins with Mike Ridley on 'The Explainability Imperative' (for AI; XAI). We need trust and accountability because machine learning is consequential. It has an impact on our lives. Why isn't explainability the default?
His explainability priorities for LAM: HCXAI; Policy and regulation; Algorithmic literacy; Critical making.
Mike quotes 'Not everything that is important lies inside the black box of AI. Critical insights can lie outside it. Why? Because that's where the human are.' Ehsan and Riedl.
Mike – explanations should be actionable and contestable. They should enable reflection, not just acquiescence.
Algorithm literacy for LAMs – embed into information literacy programmes. Use algorithms with awareness. Create algorithms with integrity.
Policy and regulation for GLAMs – engage with policy and regulatory activities; insist on explainability as a core principle; promote an explanatory systems approach; champion the needs of the non-expert, lay person.
Critical making for GLAMs – build our own tools and systems; operationalise the principles of HCXAI; explore and interrogate for bias, misinformation and deception; optimise for social justice and equity
Mike quotes: "Technology designers are the new policymakers; we didn't elect them but their decisions determine the rules we live by." Latanya Sweeney (Harvard University, Director of the Public Interest Tech Lab)
Next: shorter talks on 'AI and collections management'. Jon Dunn and Emily Lynema shared work on AMP, an audiovisual metadata platform, built on https://usegalaxy.org/ for workflow management. (Someone mentioned https://airflow.apache.org/ yesterday – I'd love to know more about GLAMs experiences with these workflow tools for machine learning / AI)
Nice 'AI explorer' from Harvard Art Museums https://ai.harvardartmuseums.org/search/elephant presented by Jeff Steward. It's a really nice way of seeing art through the eyes of different image tagging / labelling services like Imagga, Amazon, Clarifai, Microsoft.
(An example I found: https://ai.harvardartmuseums.org/object/228608. Showing predicted tags like this is a good step towards AI literacy, and might provide an interesting basis for AI explainability as discussed earlier.)
Scott Young and Jason Clark (Montana State University) shared work on Responsible AI at Montana State University. And a nice quote from Kate Zwaard, 'Through the slow and careful adoption of tech, the library can be a leader'. They're doing 'irresponsible AI scenarios' – a bit like a project pre-mortem with a specific scenario e.g. lack of resources.
Emmanuel A. Oduagwu from the Department of Library & Information Science, Federal Polytechnic, Nigeria, calls for realistic and sustainable collaborations between developing countries – library professionals need technical skills to integrate AI tools into library service delivery; they can't work in isolation from ICT. How can other nations help?
Finally, Leo Lo and Cynthia Hudson Vitale presented draft guiding principles from the US Association of Research Libraries (ARA). Points include the need to include human review; prioritise the safety and privacy of employees and users; prioritise inclusivity; democratise access to AI and be environmentally responsible.
Technology job listings for cultural heritage or the humanities aren't always easy to find. I've recently been helping recruit into various tech roles at the British Library while also answering questions from folk looking for work in the digital heritage / GLAM (galleries, libraries, archives, museums) tech / digital humanities (DH)-ish world, so I've collated some notes on where to look for job ads. Plus, some bonus thoughts on preparing for a job search and applying for jobs.
Preparing for a job search / post
If you're looking for work, setting up alerts or subscribing to various job sites can give you a sense of what's out there, and the skills and language you'd want to include in your CV or portfolio. If you're going to advertise vacancies, it helps to get a sense of how others describe their jobs.
Open Hack London, back in the day
Lurking on slacks and mailing lists gives you exposure to local jargon. Even better, if you can post occasionally to help someone with a question, as people might recognise your name later. Events – meetups, conferences, seminars, etc – can be good for meeting people and learning more about a sector. Serendipitous casual chats are easier in-person, but online events are more accessible.
Applying for GLAM/DH jobs
You probably know this, but sometimes a reminder helps… it's often worth applying for a job where you have most, but not all of the required skills. Job profiles are often wish lists rather than complete specs. That said, pay attention to the language used around different 'essential' vs 'desirable' requirements as that can save you some time.
Please, please pay attention to the questions asked during the application process and figure out (or ask) how they're shortlisting based on the questions they ask. At the BL we can only shortlist with information that applicants provide in response to questions on the application. In other places, reflecting the language and specific requirements in the job ad and profile in your cover letter matters more. And I'm sorry if you've spent ages on it, but never assume that people can see your CV during the shortlisting or interview process.
If you see a technology or method that you haven't tried, getting familiar with it before an interview can take you a long way. Download and try it, watch videos, whatever – showing willing and being able to relate it to your stronger skills helps.
The UK GLAM sector tends not to be able to offer visa sponsorship, but remote contracts may be possible. Always read the fine print…
Translate job descriptions and profiles to help candidates understand your vacancy
Updating to add: public organisations often have obscure job titles and descriptions. You can help translate jargon and public / charity / arts / academic sector speak into something closer to the language potential candidates might understand by writing blogposts and social media / discussion list messages that explain what the job actually involves, why it exists, and what a typical day or week might look like.
Cultural Heritage/Digital Humanities Slacks – most of these have jobs channels
My favourite analogy for AI / machine learning-based tools[1] is that they’re like working with a child. They can spin a great story, but you wouldn’t bet your job on it being accurate. They can do tasks like sorting and labelling images, but as they absorb models of the world from the adults around them you’d want to check that they haven’t mistakenly learnt things like ‘nurses are women and doctors are men’.
Libraries and other GLAMs have been working with machine learning-based tools for a number of years, cumulatively gathering evidence for what works, what doesn’t, and what it might mean for our work. AI can scale up tasks like transcription, translation, classification, entity recognition and summarisation quickly – but it shouldn’t be used without supervision if the answer to the question ‘does it matter if the output is true?’ is ‘yes’.[2] Training a model and checking the results of an external model both require resources and expertise that may be scarce in GLAMs.
But the thing about toddlers is that they’re cute and fun to play with. By the start of 2023, ‘generative AI’ tools like the text-to-image tool DALL·E 2 and large language models (LLMs) like ChatGPT captured the public imagination. You’ve probably heard examples of people using LLMs as everything from an oracle (‘give me arguments for and against remodelling our kitchen’) to a tutor (‘explain this concept to me’) to a creative spark for getting started with writing code or a piece of text. If you don’t have an AI strategy already, you’re going to need one soon.
The other thing about toddlers is that they grow up fast. GLAMs have an opportunity to help influence the types of teenagers then adults they become – but we need to be proactive if we want AI that produces trustworthy results and doesn’t create further biases. Improving AI literacy within the GLAM sector is an important part of being able to make good choices about the technologies we give our money and attention to. (The same is also true for our societies as a whole, of course).
Since the 2017 summit, I’ve found myself thinking about ‘collections as data’ in two ways.[3] One is the digitised collections records (from metadata through to full page or object scans) that we share with researchers interested in studying particular topics, formats or methods; the other is the data that GLAMs themselves could generate about their collections to make them more discoverable and better connected to other collections. The development of specialist methods within computer vision and natural language processing has promise for both sorts of ‘collections as data’,[4] but we still have much to learn about the logistical, legal, cultural and training challenges in aligning the needs of researchers and GLAMs.
The buzz around AI and the hunger for more material to feed into models has introduced a third – collections as training data. Libraries hold vast repositories of historical and contemporary collections that reflect both the best thinking and the worst biases of the society that produced them. What is their role in responsibly and ethically stewarding those collections into training data (or not)?
As we learn more about the different ‘modes of interaction’ with AI-based tools, from the ‘text-grounded’, ‘knowledge-seeking’ and ‘creative’,[5] and collect examples of researchers and institutions using tools like large language models to create structured data from text,[6] we’re better able to understand and advocate for the role that AI might play in library work. Through collaborations within the Living with Machines project, I’ve seen how we could combine crowdsourcing and machine learning to clear copyright for orphan works at scale; improve metadata and full text searches with word vectors that help people match keywords to concepts rather than literal strings; disambiguate historical place names and turn symbols on maps into computational information.
Our challenge now is to work together with the Silicon Valley companies that shape so much of what AI ‘knows’ about the world, with the communities and individuals that created the collections we care for, and with the wider GLAM sector to ensure that we get the best AI tools possible.
[1] I’m going to use ‘AI’ as a shorthand for ‘AI and machine learning’ throughout, as machine learning models are the most practical applications of AI-type technologies at present. I’m excluding ‘artificial general intelligence’ for now.
[2] Tiulkanov, “Is It Safe to Use ChatGPT for Your Task?”
[3] Much of this thinking is informed by the Living with Machines project, a mere twinkle in the eye during the first summit. Launched in late 2018, the project aims to devise new methods, tools and software in data science and artificial intelligence that can be applied to historical resources. A key goal for the Library was to understand and develop some solutions for the practical, intellectual, logistical and copyright challenges in collaborative research with digitised collections at scale. As the project draws to an end five and a half years later, I’ve been reflecting on lessons learnt from our work with AI, and on the dramatic improvements in machine learning tools and methods since the project began.
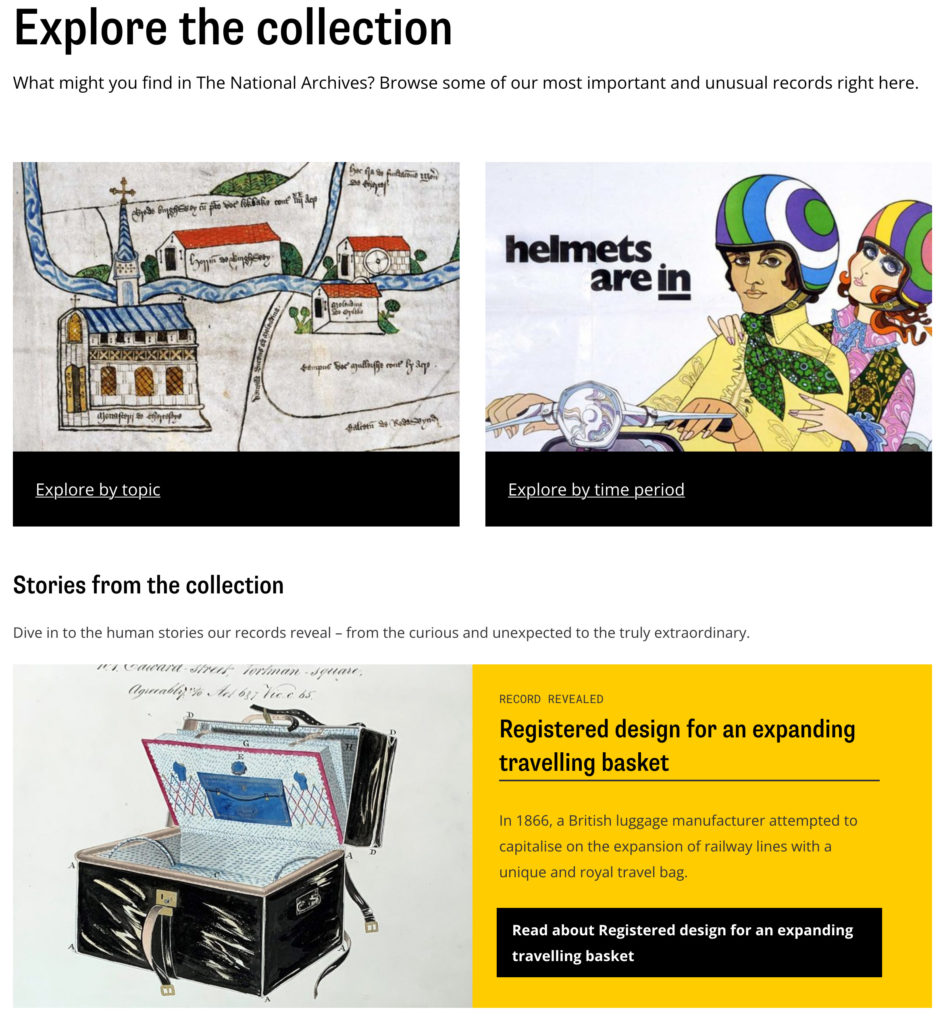
It features highlights from their collections and 'stories behind our records'. The front page offers options to explore by topic (based on the types of records that TNA holds) and time period. It also has direct links to individual stories, with carefully selected images and preview text. Three clicks in and I was marvelling at a 1904 photo from a cotton mill, and connecting it to other knowledge.
When you click into a story about an individual record, there's a 'Why this record matters' heading, which reminds me of the Australian model for a simple explanation of the 'significance' of a collection item. Things get a bit more traditional 'catalogue record online' when you click through to the 'record details' but overall it's an effective path that helps you understand what's in their collections.
The simplicity of getting to an interesting items has made me wonder about a new UX metric for collections online – 'time to curiosity inspired', or more accurately 'clicks to curiosity triggered'. 'Clicks to specific item' is probably a more common metric for catalogue-based searches, but this is a different type of invitation to explore a collection via loosely themed stories.
The Museums Computer Group's annual conference has been an annual highlight for some years now, and in 2022 I donned my mask and went to their in-person event. And only a few months later I'm posting this lightly edited version of my Mastodon posts from the day of the event in November 2022… Notes in brackets are generally from the original toots/posts.
This was the first event that I live-blogged on Mastodon rather than live-tweeting. I definitely missed the to-and-fro of conversation around a hashtag, as in mid-November Mastodon was a lot quieter than it is even a few weeks later. Anyway, on with the post!
I'm at the Museums Computer Group's #MuseTech2022 conference.
Keynote Kati Price on the last two and a half years – a big group hug or primal scream might help!
She's looking at the consequences of the pandemic and lockdowns in terms of: collaboration, content, cash, churn
Widespread adoption of tools as people found new ways of collaborating from home
Content – the 'hosepipe of requests' for digital content is all too familiar. Lockdown reduced things to one unifying goal – to engage audiences online
(In hindsight, that moment of 'we must find / provide entertainment online' was odd – the world was already full of books, tv, podcasts, videos etc – did we want things we could do together that were a bit like things we'd do IRL?)
V&A moved to capture their Kimono exhibition to share online just before closing for lockdown. Got a Time Out 'Time In'. No fancy tech, just good storytelling
V&A found that people either wanted very short or long form content; some wanted informative, others light-hearted content
Cash – how do you keep creating great experiences when income drops? No visitors, no income.
Churn – 'the great resignation' – we've seen a brain drain in the #MuseTech / GLAM sector, especially as it's hard to attract people given salaries. Not only in tech – loss of expert collections, research staff who help inform online content
UK's heading into recession, so more cuts are probably coming. What should a digital team look like in this new era?
Also, we're all burnt out. (Holler!) Emotional reserves are at an all-time low.
(Thinking about the silos – I feel my work-social circles are dwindling as I don't run into people around the building now most people are WFH most of the time)
Back from the break at #MuseTech2022 for more #MuseTech goodness, starting with Seb Chan and Indigo Holcombe-James on ACMI's CEO Digital Mentoring Program – could you pair different kinds of organisations and increase the digital literacy of senior leaders?
Working with a mentor had tangible and intangible benefits (in addition to making time for learning and reflection). The next phase was shorter, with fewer people. (Context for non-Australians – Melbourne's lockdown was *very* long and very restrictive)
(I wonder what a 'minimum viable mentorship' model might be – does a long coffee with someone count? I've certainly had my brain picked that way by senior leaders interested in digital participation and strategy)
Lessons – cross-art form conversations work really well; everyone is facing similar challenges
(Side note – I'm liking that longer posts mean I'm not dashing off posts to keep up with the talks)
Next up #MuseTech2022 Stephanie Bertrand https://twitter.com/sbrtrandcurator on prestige and aesthetic judgement in the art world. Can you recruit the public's collective intelligence to discover artworks? But can you remove the influence of official 'art world' taste makers in judging artworks?
'Social feedback is a catch-22' – can have runaway inequality where popular content becomes more popular, and artificial manipulation that skews what's valued?
Now Somaya Langley https://twitter.com/criticalsenses on making digital preservation an everyday thing. (Shoutout to the awesome #DigiPres folk who do this hard work) – how can a whole organisation include digital preservation in its wider thinking about collections and corporate records? What about collecting born-digital content so prevalent in modern life?
(Side note – Australia seems to have a much stronger record management culture within GLAMs than in the UK, where IME you really have to search to find organisational expectations about archiving project records)
Moving from Projects to Programmes to Business as Usual is hard
Help people be comfortable with there not being one right answer, and ok with 'it depends'
#MuseTech2022 Next up in Session 2: Collections; Craig Middleton, Caroline Wilson-Barnao, Lisa Enright – documenting intense bushfires in Aus summer 2019/20 and COVID. They used Facebook as a short-term response to the crisis; planned a physical exhibition but a website came to seem more appropriate as COVID went on. https://momentous.nma.gov.au has over 300 unique responses. FB helpful for seeing if a collecting idea works while it's timely, but other platforms better for sustained engagement. Also need to think about comfort levels about sharing content changing as time goes on.
Museums can be places to have difficult conversations, to help people make sense of crises. But museums also need to think beyond physical spaces and include digital from the start.
Also hard when museum people are going through the same crises (links back to Kati's keynote about what we lived through as a sector working for our audiences while living through the pando ourselves)
#MuseTech2022 David Weinczok 'using digital media to go local'
60% of National Museums Scotland's online audiences have never visited their museums. 'Telling the story of an object without the context of the landscape and community it came from' can help link online and in-person audiences and experiences
Blog series 'Objects in Place' – found items in collections from a particular area, looked to tell stories with objects as 'connective threads', not the focus in themselves
'What can we do online to make connections with people and communities offline?'
(So many speakers are finishing with questions – I love this! Way to make the most of being in conversation with the musetech community here)
Next at #MuseTech2022, Amy Adams & Karen Clarke, National Museum of the Royal Navy – digital was always lower priority before COVID; managed to do lots of work on collections data during lockdowns.
They finally got a digital asset management (DAM) system, but then had to think about maintaining it; explaining why implementation takes time. Then there was an expectation that they could 'flip a switch' and put all the collections online. Finding ways to have positive conversations with folk who are still learning about the #MuseTech field.
Also doing work on 'addressing empires' – I like that framing for a very British institution.
Now Rebecca Odell, Niti Acharya, Hackney Museum on surviving a cyber attack. Lost access to collections management database (CMS) and images. Like their digital building had burnt down. Stakeholder and public expectations did not adjust accordingly! 14 months without a CMS.
Know where your backups are! Export DBs as CSV, store it externally. LOCKSS, hard drives
#MuseTech2022 Rebecca Odell, Niti Acharya, Hackney Museum continued – reconstructing your digital stuff from backups, exports, etc takes tiiiiiiime and lots of manual work. The sector needs guides, checklists, templates to help orgs prepare for cyber attacks.
(Lots of her advice also applies to your own personal digital media, of course. Back up your backups and put them lots of places. Leave a hard drive at work, swap one with a friend!)
New Q&A game – track the echo between remote speakers and the AV system in the back. Who's unmuted that should be muted? [One of the joys of a hybrid conference]
We'll be heading out to lunch soon, including the MCG annual general meeting
Adam Coulson (National Museums Scotland) on QR codes: * weren't scanned in all exhibition/gallery contexts * use them to add extra layers, not core content * don't assume everyone will scan * discourage FOMO (explain what's there) * consider precious battery life
Now Sian Shaw (Westminster Abbey) on no longer printing 12,000 sheets of paper a week (given out to visitors with that day's info). Made each order of service (dunno, church stuff, I am a heathen) at the same URL with templates to drop in commonly used content like hymns
It's a web page, not an app – more flexible, better affordances re your place on the page
Some loved the move to sustainability but others don't like having phones out in church.
Ultimately, be led by the problem you're trying to solve (and there's always a paper backup for no/dead phone folk)
Q&A discussion – take small steps, build on lessons learnt
#MuseTech2022 Onto the final panel, 'Funding digital – what two years worth of data tells us'
(It's funny when you have an insight into your own #MuseTech2022 life via a remark at a conference – the first ever museum team I worked in was 'Outreach' at Melbourne Museum, which combined my digital team with the learning team under the one director. I've always known that working in Outreach shaped my world view, but did sitting next to the learning team also shape it?)
And now Daf James is finishing with thanks for the committee members behind the MCG generally and the event in particular – big up @irny for keeping the tech going in difficult circumstances!
Daf James welcomes online and in-person attendees to the Museums Computer Group's Museums+Tech 2022 conference
This is a 'work in progress' post that I hope to add to as I gather information about national portals for crowdsourcing / citizen science / citizen history and other forms of voluntary digital / online participation.
While portals like SciStarter and platforms like Zooniverse, FromThePage, HistoryPin etc are a great way to search across projects for something that matches your interests, I'm interested in the growth of national portals or indexes to projects (they might also be called 'project finders'). It's not so much the sites themselves that interest me as the underlying networks of regional communities of practice, national or regional infrastructure and other signs of national support that they might variously reflect or help create. If you're interested in specific projects outside the UK-US/English-language bubble, check out Crowdsourcing the world's heritage. I've also shared a 2015 list of 'participatory digital heritage sites' that includes many crowdsourcing sites.
If you know of a national portal or umbrella organisation for crowdsourcing, please drop me a line! Last updated: Jan 16, 2025.
Austria
Jan Smeddinck emailed to share the LBG Open Innovation in Science Center https://ois.lbg.ac.at/
This post was inspired by the apparently coordinated approach in France. The Archives nationales participatives site has 'Projets collaboratifs de transcriptions, annotations et indexations' – that is, participatory national archives with collaborative transcription, annotation and indexing projects.
They also have Le réseau Particip-Arc, a 'network of actors committed to participatory science in the fields of culture', supported by the Ministry of Culture and coordinated by the National Museum of Natural History.
European Union
EU-citizen.science is a 'platform for sharing citizen science projects, resources, tools, training and much more'.
Agata Bochynska said, 'Norway has recently formed a national network for citizen science that’s coordinated by Research Council of Norway' – Nasjonalt nettverk for folkeforskning (folkeforskning translates as 'folk research' according to Google).
A Swedish national hub for everyone interested in citizen science (medborgarforskning). The project was funded by Vinnova – Sweden’s innovation agency, the University of Gothenburg, the Swedish University of Agricultural Sciences, Umeå University.
https://app.unv.org/ lists online and on-site (i.e. in-person) opportunities around the world, although some of them might stretch the definition of 'voluntary roles'.
I'm delighted to share my latest publication, a collaboration with 15 co-authors written in March and April 2021. It's the major output of my Collective Wisdom project, an AHRC-funded project I lead with Meghan Ferriter and Sam Blickhan.
We have published this first version of our collaborative text to provide early access to our work, and to invite comment and discussion from anyone interested in crowdsourcing, citizen science, citizen history, digital / online volunteer projects, programmes, tools or platforms with cultural heritage collections.
I'm curious to see how much of a difference this period of open comment makes. The comments so far have been quite specific and useful, but I'd like to know where we *really* got it right, and where we could include other examples. You need a pubpub account to comment but after that it's pretty straightforward – select text, and add a comment, or comment on an entire chapter.
Having some distance from the original writing period has been useful for me – not least, the realisation that the title should have been 'perspectives on crowdsourcing in cultural heritage and digital humanities'.